
Table of Contents
1. The $2 Million Problem Sitting in Your Claims Department
Let’s be real for a second. If you’re a CIO or operations leader at a mid-sized insurance company, you probably already know something is wrong with your document processing setup. Maybe it’s the monthly invoice from your legacy IDP vendor that seems to climb every quarter. Maybe it’s the Friday afternoon call from your IT team saying the extraction rules broke again because a new claim form variant came in. Or maybe it’s your operations manager politely — or not so politely — telling you that the team is still manually keying in data that the system should be handling automatically.
You are not alone. This is one of the most common and quietly expensive problems in insurance operations today.
Industry Reality Check Insurance companies processing over 2,000 claims daily using legacy IDP platforms report an average 40% cost overrun against original vendor projections within 36 months of deployment. The causes are almost always the same: vendor lock-in, rule brittleness, and hidden IT overhead.
This article is written specifically for decision-makers at mid-sized insurance companies — the kind running between 500 and 5,000 employees, processing anything from auto and property claims to health and liability. We’ll walk through why intelligent document processing is broken for so many companies in this space, what causes these problems at a structural level, and how a modern platform like SNOH Fusion (available at snohai.com/snoh-fusion) is fundamentally different.
2. Why IDP Fails Insurance Companies — The Root Causes
Intelligent document processing was supposed to solve the manual data-entry problem. And for the first few months after go-live, it usually does. Then reality sets in.
2.1 The Document Variation Problem
Insurance claims arrive in dozens of formats. A single auto claim might come in as a scanned PDF from a repair shop, an email attachment from the adjuster, a web form submission, or a mobile photo. Each of those sources produces a slightly different document layout. Legacy IDP platforms — including Tungsten (formerly Kofax) — rely heavily on template-based extraction. When the template doesn’t match, extraction fails.
Over time, these ‘exceptions’ pile up in a manual review queue. Your operations team, instead of being freed from data entry, becomes a full-time exception-handling workforce.
The Variation Trap A mid-sized P&C insurer we reviewed had 847 active extraction templates in their legacy IDP system — maintained by a single IT specialist. When that person left, the organisation had a six-month knowledge crisis.
2.2 The Vendor Dependency Spiral
Legacy IDP vendors are built around a services revenue model. Every customisation, every new document type, every integration update — it requires a vendor ticket, a scoping call, and a statement of work. For a mid-sized insurer, this means your IT roadmap is essentially dictated by your vendor’s queue.
Platforms like Tungsten Automation, while powerful in enterprise contexts, carry licensing costs and professional services fees that assume an IT department with dedicated IDP engineers. Most mid-sized insurers don’t have that, and they end up paying for capabilities they can’t use.
2.3 Scalability That Isn’t Really Scalable
When claim volumes spike — think a regional weather event, a new product line launch, or a merger — legacy IDP systems struggle to scale gracefully. The infrastructure is often on-premise or in a hybrid setup that requires manual provisioning. SLAs slip. Backlogs build. Customer complaints rise.
2.4 The Integration Bottleneck
Insurance operations run on a web of systems: policy management platforms, claims management tools, ERP systems, compliance databases, and business intelligence dashboards. Modern IDP should connect to all of these seamlessly. Legacy platforms typically offer connectors that are fragile, version-specific, and require middleware that adds cost and latency.
Industry Benchmark Data
| Pain Point | Impact |
| Manual exceptions due to template mismatch | 62% of claims |
| Average time to add a new document type (legacy) | 3–8 weeks |
| IT hours/month spent on rule maintenance | 40–120 hrs |
| Annual vendor support cost (mid-sized insurer) | $80K–$300K |
| Claims SLA breach rate during volume spikes | 18–35% |
Visual: How Legacy IDP Creates Operational Pain
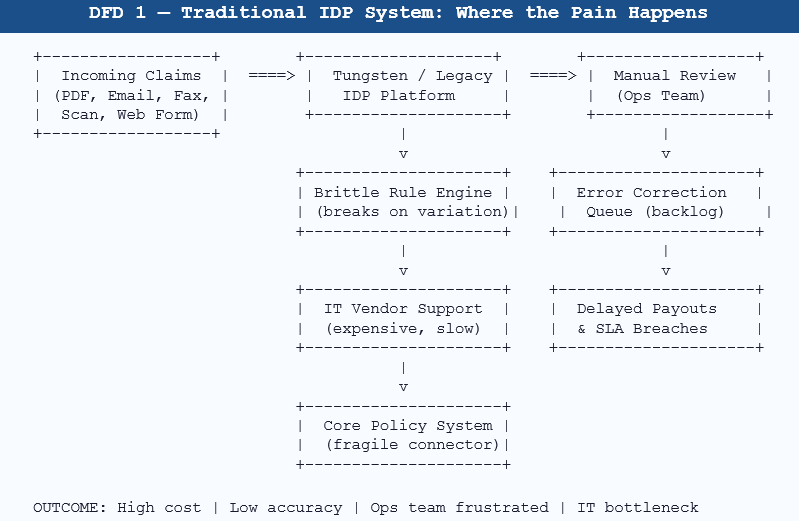
3. It’s Not Just a Technology Problem — It’s an Operations Crisis
Here’s what gets lost in the technology conversation: the real cost of a broken IDP system isn’t the licensing fee. It’s the human cost.
Your operations team is talented. They understand insurance processes, they know your customers, and they care about getting claims right. But when they’re spending 60% of their day correcting extraction errors and manually re-entering fields that a $200K software platform was supposed to handle, that talent is being wasted.
3.1 The Hidden Workforce Inside Your Exception Queue
Most insurance operations teams have developed informal workflows to compensate for IDP shortcomings. They have shared spreadsheets tracking ‘known bad’ form types. They have team members who are ‘experts’ on specific document variations. They have informal escalation paths that exist nowhere in any official process document.
This shadow workforce is expensive, fragile, and entirely invisible to your board-level reporting. When someone leaves, that institutional knowledge walks out the door with them.
Real Scenario An operations director at a regional health insurer reported that her team of 12 processors was effectively doing 4 hours of manual IDP correction work per person per day — that’s 48 person-hours daily of work that should have been automated. Annualised, that’s over $180,000 in pure labour cost sitting inside their ‘automated’ document processing workflow.
3.2 The Compliance Risk No One Is Talking About
Manual data entry doesn’t just cost money — it creates compliance exposure. In insurance, data accuracy isn’t optional. Incorrect fields in a claim can trigger regulatory audits, customer complaints, and in some cases, legal liability. When your IDP system is generating exceptions that get corrected by tired humans under deadline pressure, error rates rise. And when your auditor asks for the extraction confidence scores on those corrected records? Legacy systems often can’t provide that audit trail in a format that satisfies regulators.
4. What a Modern IDP Platform Actually Looks Like in 2026
The IDP landscape has changed dramatically in the past three years. The arrival of large language models, multi-modal AI, and cloud-native architecture has fundamentally shifted what’s possible — and what’s affordable — for mid-sized insurance organisations.
4.1 From Templates to Understanding
Modern IDP platforms don’t rely on rigid templates. They use a combination of computer vision, natural language processing, and contextual understanding to extract data from documents it has never seen before. This means when a new repair shop starts sending invoices in a different format, or when a medical provider updates their billing template, the system adapts — without a vendor ticket, without a rule update, without a three-week sprint.
4.2 Self-Learning Systems
The best platforms today get smarter over time. Every correction your operations team makes to an extraction becomes training signal for the model. After a few weeks of real usage, the system’s accuracy on your specific document types should measurably improve — the opposite of what happens with legacy rule engines, which degrade as document formats evolve.
4.3 Operations-First Design
Modern IDP is built for the people who use it, not just the IT team that configures it. Your operations managers should be able to add a new document type, adjust confidence thresholds, and monitor processing quality through a dashboard — without writing a single line of code or opening a vendor ticket.
4.4 Native Cloud Scalability
Cloud-native IDP scales automatically. When claims volume doubles during a catastrophe event, the platform provisions additional processing capacity in real time. When volume drops, it scales back down. You pay for what you use, not what you might need.
Visual: How SNOH Fusion Processes a Claim
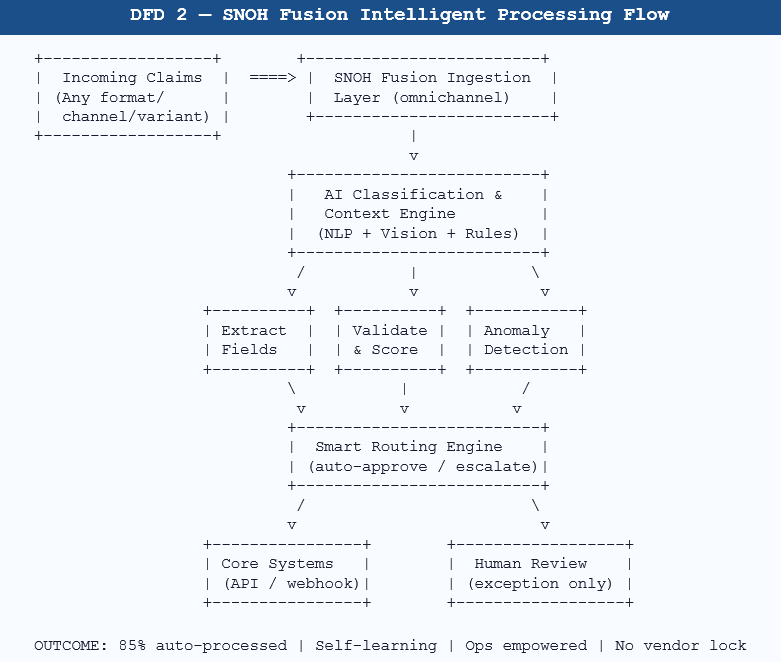
5. Introducing SNOH Fusion — Built for Insurance Operations at Scale
SNOH Fusion, available at snohai.com/snoh-fusion, is an intelligent document processing platform built specifically for the operational realities of mid-sized insurance companies. It was designed from the ground up to address the exact pain points that make legacy platforms like Tungsten unsustainable for organisations like yours.
5.1 Universal Document Ingestion
SNOH Fusion accepts documents in any format — PDFs, scanned images, email attachments, web form submissions, fax outputs, and mobile captures — through a single, unified ingestion layer. There’s no concept of ‘supported formats’ versus ‘unsupported formats.’ If it contains information relevant to a claim, SNOH Fusion can process it.
- PDF (native, scanned, mixed, password-protected)
- Image formats (JPEG, PNG, TIFF, HEIC)
- Email with attachments (parsed and contextualised together)
- Web form data (structured and semi-structured)
- EDI and HL7 feeds (for health insurance operations)
5.2 Adaptive AI Extraction Engine
At the core of SNOH Fusion is an extraction engine that combines large language model understanding with domain-specific insurance training. This means the platform understands the difference between a first notice of loss and a subrogation demand. It knows that the ‘date of loss’ on a homeowner’s claim is semantically different from the ‘service date’ on a medical bill, even when the field labels are inconsistent or absent.
Confidence scoring is granular and transparent. Your operations team can set thresholds by document type, by field criticality, and by downstream workflow requirements. High-confidence extractions route automatically. Low-confidence extractions come to the human review queue with the specific fields flagged, the extracted value highlighted, and the source location shown in the document — not a generic ‘review required’ notification.
Key Differentiator SNOH Fusion’s adaptive model doesn’t require retraining when new document variants appear. The platform uses few-shot learning to handle new templates immediately, with accuracy improving automatically as more examples are processed. Zero vendor tickets. Zero IT sprints.
5.3 Empowering Your Operations Team, Not Your IT Team
The SNOH Fusion configuration interface is built for operations managers, not engineers. Through a no-code dashboard, your team can:
- Create new document type profiles by uploading five to ten examples
- Configure routing rules based on extracted field values
- Set approval workflows with multi-level authorisation
- Monitor processing accuracy by document type, date range, and business unit
- Export audit logs in regulator-ready formats
5.4 Integration Without the Headache
SNOH Fusion offers pre-built connectors for the most common insurance technology stack components, plus a clean REST API for custom integrations. The integration layer is designed to be maintained by your internal team without vendor involvement.
Visual: SNOH Fusion Integration Architecture
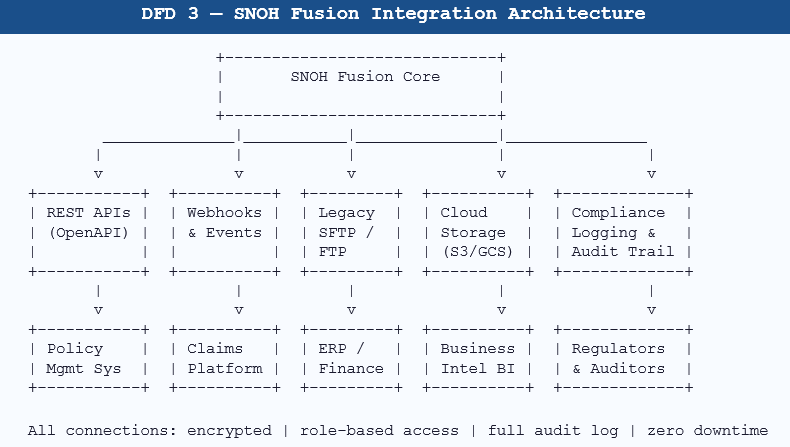
6. The Migration Conversation — What It Actually Takes
The single biggest objection we hear from CIOs considering a platform switch is migration complexity. And it’s a fair concern. If you’ve been running Tungsten or a similar legacy platform for three or more years, you have extraction templates, workflow configurations, integration mappings, and muscle memory embedded throughout your organisation.
6.1 A Phased Approach That Doesn’t Disrupt Operations
SNOH Fusion is designed to run alongside existing systems during a transition period. A phased migration typically follows this structure:
- Discovery (Weeks 1–2): Map current document types, volumes, and workflows. Identify top 20% of document types driving 80% of volume.
- Pilot (Weeks 3–6): Deploy SNOH Fusion on highest-volume document types in parallel with existing system. Compare accuracy and throughput.
- Controlled Rollout (Weeks 7–14): Expand document type coverage. Train operations team on new dashboard. Configure integration endpoints.
- Full Cutover (Week 15+): Retire legacy system for migrated document types. Maintain legacy for any residual specialised workflows until they can be ported.
6.2 What You Don’t Have to Rebuild
Unlike some platform migrations, moving to SNOH Fusion doesn’t require you to recreate hundreds of extraction templates. The platform’s adaptive AI engine learns from your historical data during the discovery phase. Your document type configurations, routing rules, and approval workflows can be recreated in the SNOH Fusion interface — typically in hours, not weeks.
Migration Reality Most mid-sized insurers complete their top 10 document types in SNOH Fusion within the first four weeks of a pilot. The remaining long-tail document types (which often represent less than 5% of total volume) can be migrated iteratively without business disruption.
7. The Business Case — ROI You Can Take to Your Board
Switching IDP platforms is a significant decision. Here’s how to frame the financial case for your leadership team.
7.1 Cost Reduction Levers
| Cost Category | Legacy | SNOH Fusion |
| Annual licensing & vendor fees | $150K–$350K | Usage-based |
| IT support hours (rule maintenance) | 40–120 hrs/mo | < 5 hrs/mo |
| Manual exception handling labour | $120K–$250K/yr | –75% reduction |
| Scalability costs during volume spikes | Emergency IT spend | Auto-scaled, $0 extra |
7.2 Revenue Impact
Faster claim processing isn’t just an efficiency metric — it’s a competitive differentiator. In personal lines insurance, claims handling speed is consistently ranked among the top three factors in customer retention and Net Promoter Score. An IDP platform that reduces claim cycle time by even 20% translates directly into measurable NPS improvement and renewal rates.
8. Compliance, Security, and Data Governance
Insurance document processing involves sensitive personal data — health information, financial records, personal identifiers. Your IDP platform isn’t just an operational tool; it’s a data governance responsibility.
8.1 What SNOH Fusion Provides
- SOC 2 Type II certified infrastructure
- GDPR and HIPAA-ready data handling with configurable data residency
- Full field-level extraction audit log with extraction timestamp, confidence score, and reviewer ID
- Role-based access controls with SSO integration (SAML 2.0, OAuth 2.0)
- Data retention policies configurable by document type and jurisdiction
- Regulator-exportable audit reports in PDF and structured data formats
8.2 The Audit Trail Your Regulator Actually Wants
When a state insurance regulator asks how a specific claim field was populated, you need to be able to answer that question with evidence. SNOH Fusion logs every extraction event with source document reference, extracted value, confidence score, and any human corrections applied. This audit trail is exportable in standard formats and retained per your configurable data governance policy.
Security Note All documents processed through SNOH Fusion are encrypted at rest (AES-256) and in transit (TLS 1.3). Document data is never used for model training without explicit customer consent, and dedicated tenant environments are available for organisations with strict data isolation requirements.
9. Getting Started — Your 30-Day Proof of Value
The best way to understand what SNOH Fusion will do for your organisation is to see it work on your actual documents. The SNOH Fusion proof-of-value programme is designed specifically for mid-sized insurance CIOs who need to validate ROI before committing to a platform migration.
What the 30-Day POV Includes
- Ingestion and processing of up to 10,000 of your actual claim documents
- Side-by-side accuracy comparison against your current IDP output
- Operations team access to the no-code configuration dashboard
- Integration test with your primary claims management or policy system
- Delivered ROI analysis report with documented accuracy rates, processing times, and projected annual savings
Start your proof of value at: snohai.com/snoh-fusion
No commitment required. No vendor RFP required. Just results.
10. Frequently Asked Questions
These are the questions we hear most from CIOs and operations leaders when they’re evaluating a move away from their current IDP platform.
Q: How long does it actually take to migrate from Tungsten to SNOH Fusion without disrupting operations?
A: Most mid-sized insurers complete a parallel migration within 8–14 weeks using our phased approach. The first document types go live in SNOH Fusion within 3–4 weeks, typically handling 60–70% of your total claim volume. Legacy systems can run in parallel for as long as needed, so there is no forced cutover date and no operational risk to your SLAs during transition. Visit snohai.com/snoh-fusion for a migration timeline specific to your document volume.
Q: Our IT team is not large — can our operations managers actually configure SNOH Fusion without engineering support?
A: Yes, and this is one of the core design principles behind SNOH Fusion. The configuration dashboard is built for operations managers, not engineers. Adding a new document type, adjusting confidence thresholds, building routing workflows, and exporting audit reports are all no-code activities. Most operations teams are self-sufficient after a two-day onboarding session. IT is only involved for initial API integration setup and SSO configuration.
Q: We process health, auto, and property claims — all very different document types. Can one platform handle all of them?
A: Absolutely. SNOH Fusion is built to handle heterogeneous document environments. The platform maintains separate extraction profiles for each document type, with domain-specific training for health (including HL7/HIPAA formats), auto (repair estimates, police reports, accident forms), and property (inspection reports, contractor invoices, weather data). Many of our insurance customers process 15 or more distinct document types through a single SNOH Fusion deployment.
Q: What happens when a completely new document format comes in that the system has never seen?
A: SNOH Fusion’s adaptive AI engine handles unseen document variants in real time using contextual inference rather than template matching. If the system’s confidence on a new format falls below your configured threshold, it routes to human review with the specific low-confidence fields flagged. Your operations team corrects the extraction, and that correction immediately improves the model’s accuracy for similar documents going forward — typically reaching high-confidence auto-processing for a new document type within 50–100 examples.
Q: How does SNOH Fusion integrate with our existing claims management platform and policy system?
A: SNOH Fusion provides pre-built connectors for major insurance platforms and a clean REST API for custom integrations. The API is documented to OpenAPI 3.0 standard and supports webhook notifications, batch export, and real-time event streaming. Most integration projects are completed in one to two weeks by your internal IT team without vendor professional services. See the integration documentation at snohai.com/snoh-fusion.
Q: How is SNOH Fusion pricing structured compared to our current per-page licensing model?
A: SNOH Fusion uses a usage-based pricing model based on document volume processed, with no per-field or per-document-type fees. There are no minimum template counts, no charges for configuration changes, and no professional services fees for routine operation. Most mid-sized insurers see a 35–55% reduction in total IDP spend in year one, with further savings as auto-processing rates improve. Pricing details and ROI modelling are available at snohai.com/snoh-fusion.
Q: We have a compliance requirement to keep claims data in-region. Can SNOH Fusion support data residency requirements?
A: Yes. SNOH Fusion supports configurable data residency with deployment options in US, EU, and APAC regions. Documents can be processed within a specific geographic boundary with no cross-region data movement. SOC 2 Type II certification, HIPAA-ready infrastructure, and GDPR-compliant data handling are standard across all deployment options.
Q: What is the accuracy rate we can realistically expect compared to our current system?
A: In comparative trials against Tungsten and similar legacy platforms, SNOH Fusion consistently achieves 15–25% higher field-level extraction accuracy on variable document types, and 40–60% reduction in manual exception rates within the first 90 days. Accuracy metrics are tracked in real time in the operations dashboard, broken down by document type and field — so you always have current, accurate visibility into system performance rather than relying on vendor-reported statistics.
Q: Our vendor contract with Tungsten runs another 18 months — does it make sense to start evaluating SNOH Fusion now?
A: Yes, for two reasons. First, the SNOH Fusion proof-of-value programme can be run in parallel with your existing contract without any migration commitment, giving you documented ROI data well before your contract renewal decision point. Second, the cost savings and accuracy improvements you capture during a parallel operation period often offset the migration investment before your legacy contract even expires. Starting now gives you options; waiting gives your current vendor negotiating leverage at renewal.
Q: How do we get started and what does the first conversation with SNOH Fusion look like?
A: The first step is a 45-minute discovery call focused on your current document types, volumes, pain points, and technology environment. There is no sales presentation and no product demo until we understand your specific situation. After discovery, we scope a proof-of-value engagement using your actual documents. Most CIOs who go through this process have a clear ROI picture within 30 days. Start the conversation at snohai.com/snoh-fusion.
Ready to Stop Overpaying for Document Processing That Doesn’t Deliver?
The insurance companies winning in the current market aren’t just selling better products — they’re operating more efficiently. They’re processing claims faster, with fewer errors, at lower cost. And increasingly, intelligent document processing is the operational lever making that possible.
If your current IDP platform is costing you more than it should, requiring more IT support than it should, and delivering less accuracy than it should — that’s not a technology problem. That’s a platform problem. And platform problems have platform solutions.
| See SNOH Fusion in action on your documents |
snohai.com | All rights reserved