
Imagine being able to take a photo of a document and instantly convert it into editable text—no retyping, no manual data entry, just smart software doing the heavy lifting. This isn’t science fiction. It’s OCR, or Optical Character Recognition.
OCR has changed the way we use and perceive information in the modern age. Optical Character Recognition has become increasingly useful for transforming printed or handwritten material into an electronic format. Consider scanning an old book, importing data using invoices, or pulling text from an image. In any of those scenarios, Optical Character Recognition is the technology at work.
Table of Contents
What is OCR?
OCR, which refers to Optical Character Recognition, identifies and deciphers characters from photographs, scans, or written notes, allowing computers to read and manage information like text. It changes various document formats, such as PDF, digital pictures, or printed paper files, into data that can be edited and searched easily.
Simply said, OCR converts the text stored in images to an electronic format that can be altered using a computer.
Why is OCR Important?
Before OCR technology, the only means of digitizing printed texts was by typing them out – a labor-intensive process that is inefficient, riddled with errors, and time-consuming. With the advent of OCR, numerous advantages automatically arise:
- Saves Time and Effort: Data collection from physical documents, receipts, and invoices is now speedy and effortless.
- Improve Precision: Minimizes human errors associated with data entry tasks.
- Makes Data Searchable: Once the text is understood, it has the potential to be indexed and searched in the same manner as other digital files.
- Supports Automation: Employs automation in document processing, banking, healthcare, and logistics for workflow automation.
How Does OCR Work?
Essentially, OCR combines image processing, pattern recognition, and machine learning to recognize and translate text. Following is an outline of how the procedure is done:
1. Image Acquisition
An OCR scanner captures the image of a text document using a camera or scanner. OCR accuracy depends heavily on the clarity of the document image.
2. Preprocessing
Here is the list of cleaning and enhancing techniques done to the image:
- Reduction of background noise
- Straightening text that is not level
- Transferring the image to grayscale
- Adjusting lighting and contrast to set levels
3. Text Detection
The software scans the picture for different parts that comprise text. It divides the picture into rows, phrases and single letters.
4. Character Recognition
Here lies the core of the OCR. The software uses one of two methods:
- Pattern Recognition: Checking each character against known templates.
- Feature Analysis: Look through various letters and numbers’ outlines, lines, and round sections to differentiate them.
Today’s OCR technology adopts AI and machine learning for better accuracy with different handwriting, fonts, and languages.
5. Post-processing
Recognized text is edited as per its dictionaries and grammar rules which aim to fix the mistakes made on it. Formatting, whenever possible, is returned to its original state.
Read More: How does OCR work?
Types of OCR
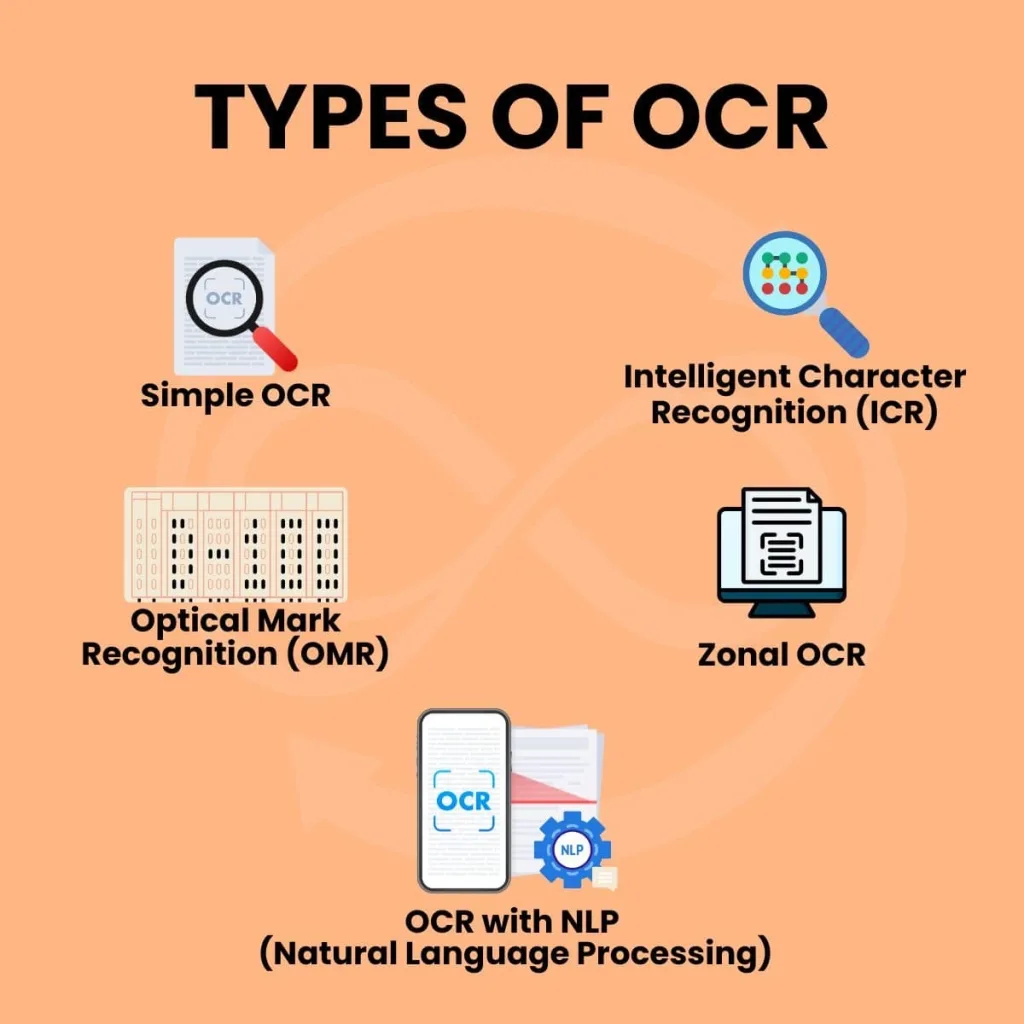
There are different types of OCR depending on the need:
1. Simple OCR: Only recognizes printed or typed characters. Works best with simple layouts.
2. Intelligent Character Recognition (ICR): Used to recognize handwritten text with AI or Neural Networks. Primarily used in forms and notes.
3. Optical Mark Recognition (OMR): Detects ticked boxes or bubbles, e.g. in MCQ exams or surveys.
4. Zonal OCR: Used to capture text from designated areas or fields of the document, such as invoice numbers or dates.
5. OCR with NLP (Natural Language Processing): This involves combining OCR with AI to provide deeper context understanding for advanced document processing.
Where is OCR Used?
Even if you are not aware of it, OCR technology permeates our daily lives. Popular uses include:
- Document Management: Scanning books, contracts, or archives so they’re stored as editable PDFs or Word documents.
- Banking and Finance: Automatic clearing of checks, reading account numbers from forms, and invoice processing.
- Logistics: Read shipping and tracking IDs and warehouse inventory.
- Healthcare: Converting patient records, prescriptions and insurance documents to digital formats.
- Search Engines: Making printed materials searchable.
- Mobile Apps: Translating text from pictures, scanning business cards, and extracting receipt data.
Know More: What is Document Management System?
Benefits of Using OCR
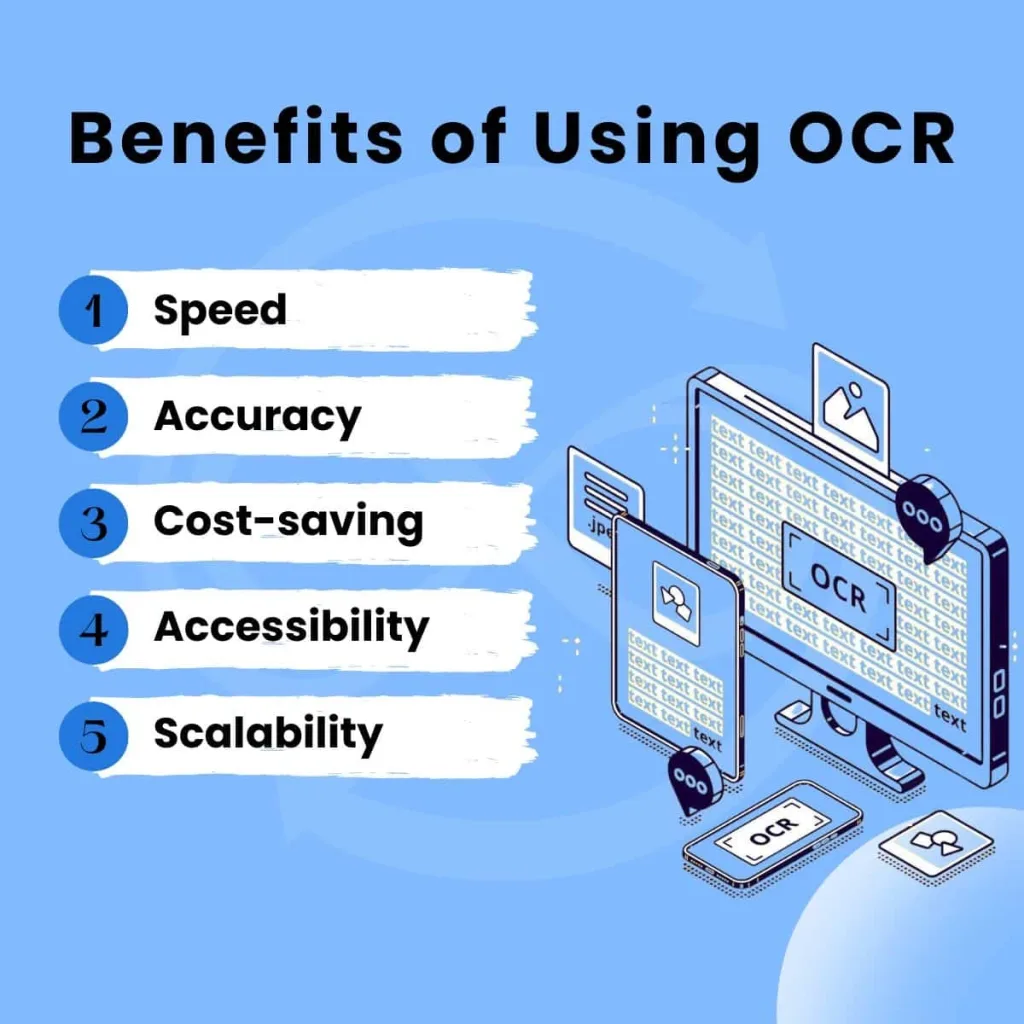
- Speed: A task that may take hours manually can be completed in seconds.
- Accuracy: Modern OCR engines today can surpass accuracy levels of 98%.
- Cost-saving: Reducing the need for human labor.
- Accessibility: Makes printed content accessible to screen readers and the visually impaired.
- Scalability: Helps organizations process thousands of documents regardless of size.
Challenges in OCR
Even if OCR systems have improved over the years, there are still existing limitations on it. For example:
- Low-Quality Images: Shrunk or blurry pictures also add to the lack of accuracy.
- Handwriting: Scrawled and cursive content is quite challenging to interpret.
- Complex Layouts: Brochures and magazines that contain both text and images can be quite confusing for most OCR software.
- Multilingual Text: Every language also has its alphabet which means different training is required for OCR systems to work with multiple languages.
That’s why so many advanced systems nowadays utilize AI, language models, and deep learning to improve contextual understanding and accuracy.
Popular OCR Tools and Software
Below are some examples of OCR tools used today:
- Google Tesseract OCR: This is one of the most popular free and open-source options available due to its heavy supporter, Google.
- Adobe Products: Adobe Products have built-in OCR systems integrated into their PDF editing tools.
- ABBYY FineReader: This OCR software works professionally and is very sought after in business settings.
- Microsoft OneNote: Another software that can remove text from images is Microsoft OneNote.
- Google Docs: Users can upload images and PDF files to Google Doc,s and it will convert these files into text, using the Google OCR system.
Conclusion
Although OCR may appear to be just a minor piece of technology, it is anything but. It is more recognized in today’s era, with numerous companies like banks and hospitals to OCR emerging alongside the new government initiatives.
Related solutions: Explore Snoh Docs for intelligent document processing, Snoh Flow for workflow automation, and talk to our team for implementation.