Introduction
AI-driven SLA prediction is one of the most operationally significant applications of machine learning in enterprise workflow management. Most organisations manage SLA compliance reactively: they configure timers, receive breach notifications, and respond after the fact. The breach has already occurred. The damage to the vendor relationship, the compliance record, or the internal stakeholder commitment is already done.
Predictive SLA management inverts this model. By analysing patterns in historical process data, a predictive engine can identify which active workflow instances are likely to breach their SLA—not based on the timer expiring, but based on behavioural signals that precede breaches in the historical record. This enables operations teams to intervene proactively: escalating at-risk tasks, reassigning to more available approvers, or flagging to process owners—before the breach clock runs out.
This guide covers how AI-driven SLA prediction works, what data it requires, how to operationalise the predictions, and how to measure its impact on breach prevention.
How Predictive SLA Models Work
Predictive SLA models are trained on historical workflow instance data: specifically, the pattern of events and timing signals that characterise instances that eventually breached their SLA versus those that completed on time.
The model learns to identify risk factors that correlate with breach outcomes—not after breach, but in the early stages of an instance’s lifecycle when there is still time to intervene. Common predictive signals include:
Time-to-first-action: How long after assignment the assignee takes any action on the task. Instances where first action is significantly delayed relative to historical norms for that assignee and task type are statistically more likely to breach.
Assignee historical completion rate: Some assignees consistently complete certain task types faster or slower than average. The model incorporates individual completion time distributions when assessing risk for a specific assignment.
Queue depth at time of assignment: Instances assigned when the assignee already has a heavy queue are more likely to breach than those assigned to a lightly loaded assignee—even if both have the same SLA window.
Time of week and calendar context: Tasks assigned late in the week, before public holidays, or during known high-volume periods (month-end close, budget cycle peaks) have higher historical breach rates. The model incorporates calendar context as a risk factor.
Task complexity signals: Certain task attributes—high transaction value, new vendor, compliance flag, multi-document attachment—correlate with longer completion times. The model weights these against the SLA window to assess risk.
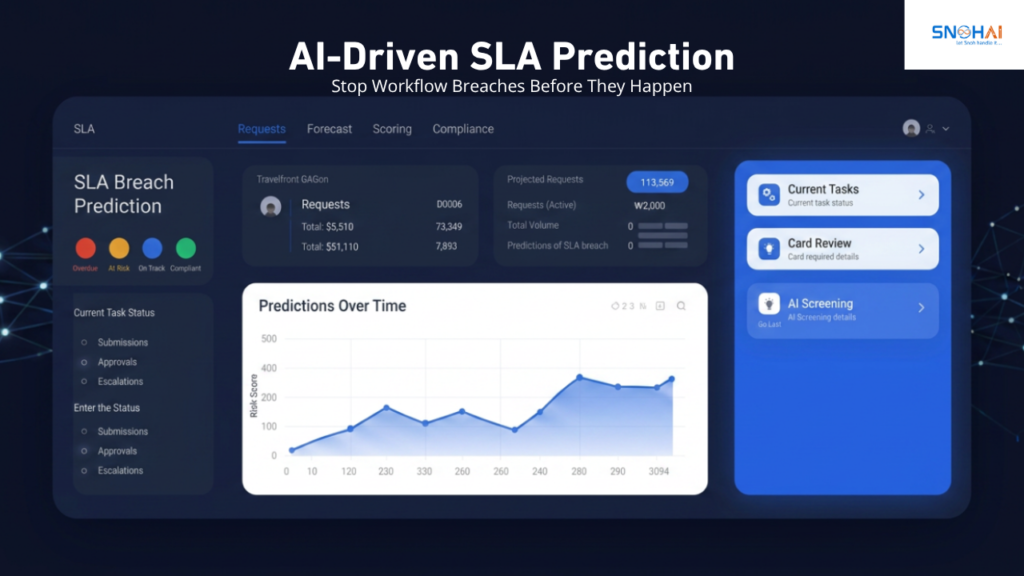
The Prediction Output: Risk Scoring Active Workflow Instances
The output of a predictive SLA model is a risk score for each active workflow instance: a probability that the instance will breach its SLA if no intervention occurs. This score is updated continuously as new signals arrive—when the assignee opens the task, when they request additional information, when a reminder is sent.
Snoh Flow’s predictive SLA engine uses historical cycle time data to flag at-risk workflows 24–48 hours before breach, giving operations teams a meaningful intervention window. This is the critical operational value of prediction: not that it tells you a breach is likely after 90% of the SLA window has elapsed, but that it identifies risk early enough for intervention to make a difference.

Risk scores can be operationalised through three response tiers:
Green (low risk): Instance tracking within normal parameters. Standard SLA timer management applies.
Amber (elevated risk): Instance showing early signals associated with breach in historical data. Trigger an early reminder to the assignee and a heads-up to their manager. No reassignment yet.
Red (high risk): Instance showing strong predictive signals for breach. Trigger immediate escalation—reassignment to backup approver or escalation to supervisor—without waiting for the SLA window to expire.
Data Requirements for Predictive SLA Management
Predictive SLA models require structured historical data from your workflow platform. The minimum data set for training a useful model includes:
- Completed workflow instances with full event logs: assignment time, first action time, completion time, all intermediate events
- SLA outcome labels: Whether each instance completed within SLA or breached, and at which step the breach occurred
- Assignee metadata: Role, department, timezone, historical completion time distributions by task type
- Task metadata: Type, complexity indicators, compliance flags, transaction value tier
The practical minimum for a useful model is typically 6–12 months of historical data with at least 500–1,000 completed instances per workflow type. Smaller data sets produce models with high variance—predictions that are unreliable because the training sample is insufficient to distinguish signal from noise.
For organisations with less historical data, a useful interim approach is to deploy rule-based early warning logic—based on known risk factors like late-week assignment or high-queue assignment—before full predictive models are trained. This captures a significant proportion of preventable breaches without requiring a mature data set.
Operationalising Predictions: The Proactive Escalation Workflow
Predictive SLA scoring is only operationally valuable if it triggers action. The most effective implementation pattern connects prediction scores directly to automated workflow responses—not to a dashboard that requires a human to monitor and interpret.
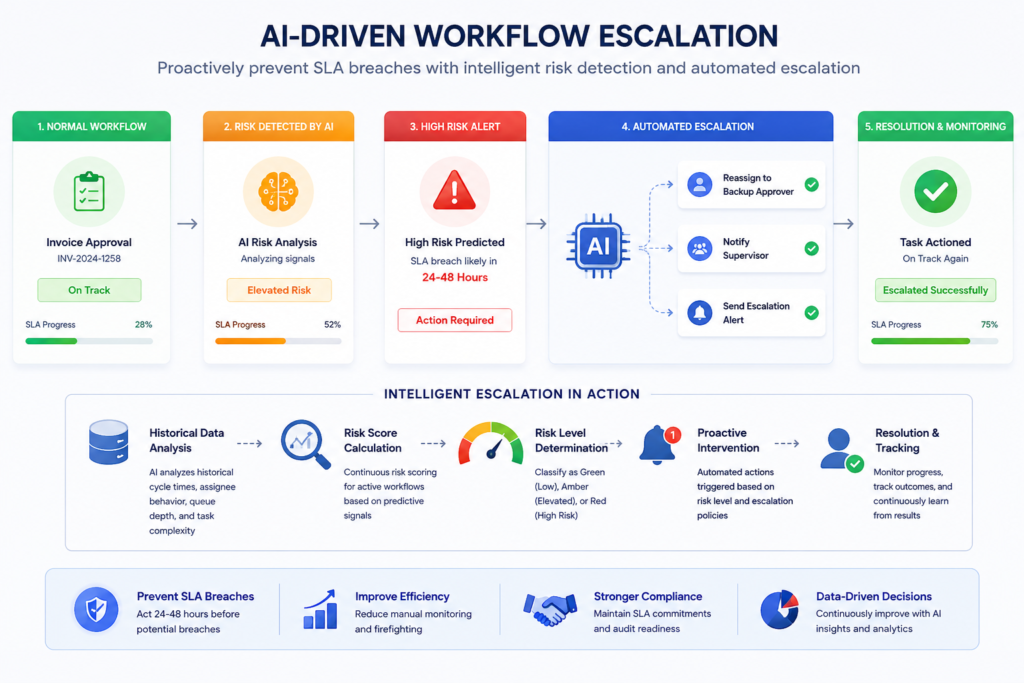
A proactive escalation workflow triggered by prediction scores should:
- Monitor all active instances continuously and recalculate risk scores as new events arrive
- Trigger amber-tier responses automatically when instances cross the elevated-risk threshold: send an early reminder, notify the team lead, update the instance’s priority indicator on the operations dashboard
- Trigger red-tier responses automatically when instances cross the high-risk threshold: execute the escalation rule (reassign to defined backup, notify escalation authority), log the predictive escalation event in the audit trail with the risk score and contributing factors
- Track prediction accuracy by recording whether each escalation prevented a breach or whether the instance breached despite escalation—feeding this outcome data back into the model
The audit trail documentation of predictive escalation events is important for two reasons: it creates an accountable record of proactive governance actions, and it generates the labeled outcome data needed to improve model accuracy over time.
Measuring Breach Prevention Effectiveness
The primary impact metrics for AI-driven SLA prediction are:
Predictive breach prevention rate: Of all instances flagged as high-risk by the model, what percentage successfully completed within SLA following proactive escalation? A mature predictive model with good intervention logic should prevent breaches in 60–80% of high-risk flagged instances.
False positive rate: Of all instances flagged as high-risk, what percentage completed on time without any intervention? High false positive rates create alert fatigue and reduce team confidence in the prediction system. Model refinement should target false positive rates below 20%.
Breach rate reduction: Overall SLA breach rate before and after predictive management deployment. This is the headline metric—but it lags the more granular metrics above and should be evaluated over rolling 90-day periods to smooth variability.
For context on the broader SLA management architecture that predictive tools sit within, our guide on SLA-based workflow escalation and automated breach prevention covers the timer and escalation framework that prediction enhances.
Conclusion
AI-driven SLA prediction shifts workflow governance from reactive breach management to proactive breach prevention. By identifying at-risk instances 24–48 hours before breach and triggering automated escalation responses, operations teams can prevent the majority of preventable SLA failures without continuous manual monitoring.
Three key takeaways:
- Predictive SLA models identify breach risk from early behavioural signals—time-to-first-action, queue depth, assignee history, and calendar context—not just from timer proximity
- Prediction is only operationally valuable when connected to automated escalation responses; a dashboard of risk scores that requires human monitoring captures only a fraction of the prevention potential
- Model accuracy improves with data volume and outcome feedback; early deployments should be supplemented with rule-based early warnings until sufficient training data is available
FAQ
What machine learning techniques are used for SLA prediction?
The most common approaches are gradient boosting models (XGBoost, LightGBM) trained on structured workflow event features, and survival analysis models that estimate the probability of completing within the SLA window given current elapsed time and task features. Survival analysis is particularly well-suited to SLA prediction because it natively handles the time-to-event nature of the problem. Both approaches require structured, labelled historical data and feature engineering that incorporates workflow-specific domain knowledge.
How does predictive SLA management handle workflow types with insufficient historical data?
For new workflow types or low-volume processes with limited history, statistical prediction is unreliable. The practical approach is to deploy rule-based early warning logic first—flagging instances based on known risk factors (late-week assignment, high queue depth, new task type) until sufficient data is available for model training. Clearly communicate to operations teams which workflows are operating under rule-based versus predictive logic, to set appropriate expectations for alert reliability.
Can predictive SLA models account for seasonal workload variations?
Yes, with sufficient historical data. Models trained on 12+ months of data can incorporate seasonal patterns—month-end close periods, annual budget cycles, holiday periods—as features that affect breach probability. Models trained on shorter windows may not capture seasonal effects reliably. When deploying in the first year, supplement model predictions with manually configured seasonal escalation rules to cover known high-risk periods.
How is a predictive escalation documented for compliance purposes?
Predictive escalation events should be logged in the workflow audit trail with the following metadata: the risk score at the time of escalation, the top contributing factors (as machine-readable feature importances), the automated action taken (reassignment, notification, priority change), the new assignee, and the outcome (breach prevented, breach occurred despite escalation). This documentation demonstrates that the escalation was governance-driven, not arbitrary, and provides the outcome data needed for model improvement.
What is the difference between predictive SLA management and real-time SLA monitoring?
Real-time SLA monitoring tracks active instances against their timer windows—showing which instances are at 50%, 75%, or 90% of their SLA window. This is useful for situational awareness but does not identify risk until the timer is already significantly elapsed. Predictive SLA management identifies risk based on behavioural signals that precede timer-based risk—enabling intervention earlier, when there is more time for the intervention to succeed. The two are complementary: monitoring provides the operational dashboard; prediction provides the early warning system.